
| Citation: |
Anlin Liu, Lei Liu, Jinde Cao, Fawaz E. Alsaadi. DEEP DETERMINISTIC POLICY GRADIENT WITH GENERALIZED INTEGRAL COMPENSATOR FOR HEIGHT CONTROL OF QUADROTOR[J]. Journal of Applied Analysis & Computation, 2022, 12(3): 868-894. doi: 10.11948/20210442

|
DEEP DETERMINISTIC POLICY GRADIENT WITH GENERALIZED INTEGRAL COMPENSATOR FOR HEIGHT CONTROL OF QUADROTOR
-
Abstract
This paper is corned with the desired height control of the quadrotor under the framework of deep deterministic policy gradient with prioritized experience replay (PER-DDPG) algorithm. The reward functions are designed based on an out-of-bounds plenty mechanism. By introducing a generalized integral compensator to the actor-critic structure, the PER-DDPG-GIC algorithm is proposed. The quadrotor is controlled by a neural network trained by the proposed PER-DDPG-GIC algorithm, which maps the system state to control commands directly. The simulation results demonstrate that introduction of generalized integral compensator mechanism can effectively reduce the steady-state error and the reward has been greatly enhanced. Moreover, the generalization ability and robustness, with respect to quadrotor models with different weights and sizes, have also been verified in simulations.
-
-
References
[1] G. M. Barros and E. L. Colombini, Using soft actor-critic for low-level uav control, 2020. [2] L. Cao, X. Hu, S. Zhang and Y. Liu, Robust flight control design using sensor-based backstepping control for unmanned aerial vehicles, Journal of Aerospace Engineering, 2017, 30(6), 04017068. doi: 10.1061/(ASCE)AS.1943-5525.0000783 [3] X. Cao, H. Wan, Y. Lin and S. Han, High-value prioritized experience replay for off-policy reinforcement learning, in 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), 2019. [4] A. Das, K. Subbarao and F. Lewis, Dynamic inversion with zero-dynamics stabilisation for quadrotor control, IET Control Theory & Applications, 2009, 3(3), 303-314. [5] T. De Bruin, J. Kober, K. Tuyls and R. Babuska, Experience selection in deep reinforcement learning for control, 2018. [6] T. Dierks and S. Jagannathan, Output feedback control of a quadrotor uav using neural networks. , IEEE Transactions on Neural Networks, 2009, 21(1), 50-66. [7] A. R. Dooraki and D. J. Lee, An innovative bio-inspired flight controller for quad-rotor drones: Quad-rotor drone learning to fly using reinforcement learning, Robotics and Autonomous Systems, 2021, 135, 103671. doi: 10.1016/j.robot.2020.103671 [8] N. T. Duc, Q. Hai, D. N. Van et al., An approach for UAV indoor obstacle avoidance based on AI technique with ensemble of ResNet8 and Res-DQN, in 2019 6th NAFOSTED Conference on Information and Computer Science (NICS), 2019. [9] J. Ghommam, M. Saad, S. Wright and M. Quan, Relay manoeuvre based fixed-time synchronized tracking control for UAV transport system, Aerospace Science and Technology, 2020, 103, 105887. doi: 10.1016/j.ast.2020.105887 [10] U. H. Ghouri, M. U. Zafar, S. Bari et al., Attitude control of quad-copter using deterministic policy gradient algorithms (DPGA), in 2019 2nd International Conference on Communication, Computing and Digital systems (C-CODE), IEEE, 2019, 149-153. [11] J. Han, From PID to active disturbance rejection control, IEEE Transactions on Industrial Electronics, 2009, 56(3), 900-906. doi: 10.1109/TIE.2008.2011621 [12] H. Hasselt, Double q-learning, Advances in neural information processing systems, 2010, 23, 2613-2621. [13] Y. Hou, L. Liu, Q. Wei et al., A novel ddpg method with prioritized experience replay, in 2017 IEEE international conference on systems, man, and cybernetics (SMC), IEEE, 2017, 316-321. [14] H. Hu and Q. Wang, Proximal policy optimization with an integral compensator for quadrotor control, Frontiers of Information Technology & Electronic Engineering, 2020, 21, 777-795. [15] Y. Jiang, Z. Mi and H. Wang, An improved OLSR protocol based on task driven used for military UAV swarm network, Intelligent Robotics and Applications, 2019. [16] S. Kapturowski, G. Ostrovski, J. Quan et al., Recurrent experience replay in distributed reinforcement learning, in International conference on learning representations, 2018. [17] W. Koch, R. Mancuso, R. West and A. Bestavros, Reinforcement learning for UAV attitude control, ACM Transactions on Cyber-Physical Systems, 2019, 3(2), 1-21. [18] L. Liu, B. Tian, X. Zhao and Q. Zong, UAV autonomous trajectory planning in target tracking tasks via a dqn approach, in 2019 IEEE International Conference on Real-time Computing and Robotics (RCAR), 2019. [19] A. Y. Ng, D. Harada and S. Russell, Policy invariance under reward transformations: Theory and application to reward shaping, in Icml, 99, 1999, 278-287. [20] C. Peng, Y. Bai, X. Gong et al., Modeling and robust backstepping sliding mode control with Adaptive RBFNN for a novel coaxial eight-rotor UAV, IEEE/CAA Journal of Automatica Sinica, 2015, 2(1), 56-64. doi: 10.1109/JAS.2015.7032906 [21] S. Santos, C. L. Nascimento and S. N. Givigi, Design of attitude and path tracking controllers for quad-rotor robots using reinforcement learning, in Aerospace Conference, 2012. [22] T. Schaul, J. Quan, I. Antonoglou and D. Silver, Prioritized experience replay, arXiv preprint arXiv: 1511.05952, 2015. [23] M. Z. Shah, R. Samar and A. I. Bhatti, Guidance of air vehicles: A sliding mode approach, IEEE Transactions on Control Systems Technology, 2015, 23(1), 231-244. doi: 10.1109/TCST.2014.2322773 [24] F. Shang, H. Chou, S. Liu and X. Wang, A framework of power pylon detection for UAV-based power line inspection, in 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), IEEE, 2020, 350-357. [25] D. Silver, G. Lever, N. Heess et al., Deterministic policy gradient algorithms, in International conference on machine learning, PMLR, 2014, 387-395. [26] A. K. Tiwari and S. V. Nadimpalli, Augmented random search for quadcopter control: An alternative to reinforcement learning, in International Journal of Information Technology and Computer Science(IJITCS), 2019. [27] H. Van Hasselt, A. Guez and D. Silver, Deep reinforcement learning with double q-learning, in Proceedings of the AAAI Conference on Artificial Intelligence, 30, 2016. [28] Y. Wang, J. Sun, H. He and C. Sun, Deterministic policy gradient with integral compensator for robust quadrotor control, IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019, 50(10), 3713-3725. [29] Z. Wang, V. Bapst, N. Heess et al., Sample efficient actor-critic with experience replay, arXiv preprint arXiv: 1611.01224, 2016. [30] S. L. Waslander, G. M. Hoffmann, J. Jang and C. J. Tomlin, Multi-agent quadrotor testbed control design: integral sliding mode vs. reinforcement learning, in IEEE/RSJ International Conference on Intelligent Robots & Systems, 2005. [31] H. Yin and S. Pan, Knowledge transfer for deep reinforcement learning with hierarchical experience replay, in Proceedings of the AAAI Conference on Artificial Intelligence, 31, 2017. [32] B. Zhao, B. Xian, Y. Zhang and X. Zhang, Nonlinear robust adaptive tracking control of a quadrotor UAV via immersion and invariance methodology, IEEE Transactions on Industrial Electronics, 2015, 62(5), 2891-2902. doi: 10.1109/TIE.2014.2364982 [33] J. Zhao, Y. Li, D. Hu and Z. Pei, Design on altitude control system of quad rotor based on laser radar, in 2016 IEEE International Conference on Aircraft Utility Systems (AUS), IEEE, 2016, 105-109. [34] N. Zhen, N. Malla and X. Zhong, Prioritizing useful experience replay for heuristic dynamic programming-based learning systems, IEEE Transactions on Cybernetics, 2018, 49(11), 3911-3922. -
-
Figures(24) / Tables(5)
Export File
Citation
Anlin Liu, Lei Liu, Jinde Cao, Fawaz E. Alsaadi. DEEP DETERMINISTIC POLICY GRADIENT WITH GENERALIZED INTEGRAL COMPENSATOR FOR HEIGHT CONTROL OF QUADROTOR[J]. Journal of Applied Analysis & Computation, 2022, 12(3): 868-894. doi: 10.11948/20210442
Format
Content
 DownLoad:
DownLoad:
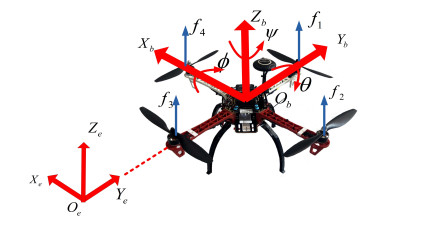
- Figure 1. Structure and frames of the quadrotor.
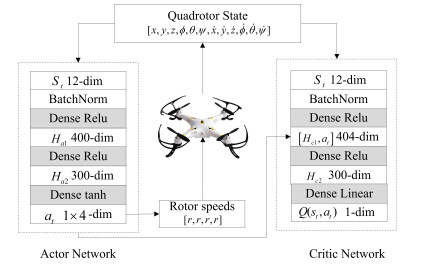
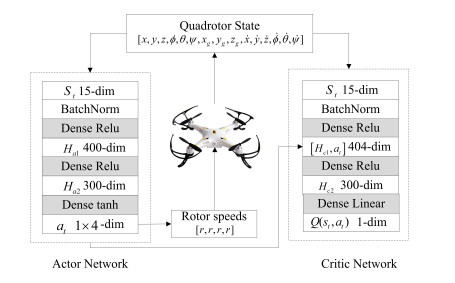
- Figure 2. Actor-critic network of DDPG for quadrotor control.
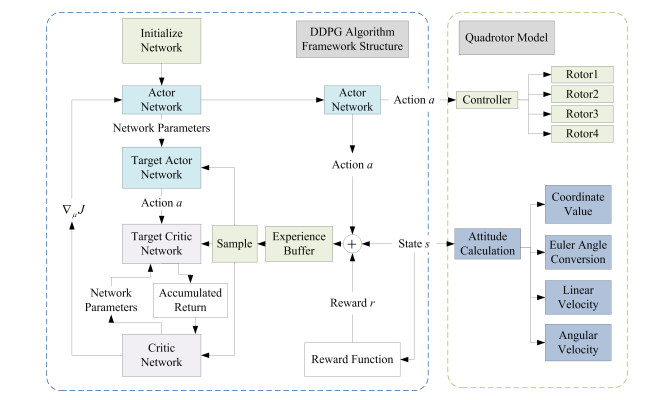
- Figure 3. System network framework structure.
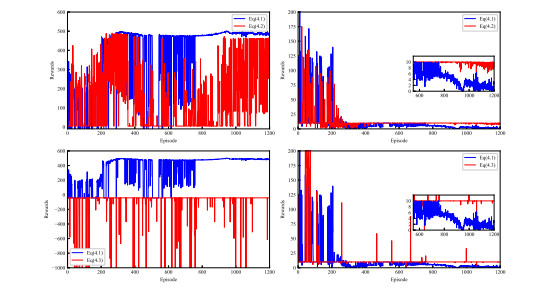
- Figure 4. Comparison of accumulated reward and steady-state error of different reward functions
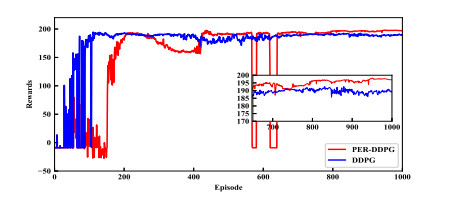
- Figure 5. Accumulated reward comparison between DDPG and PER-DDPG.
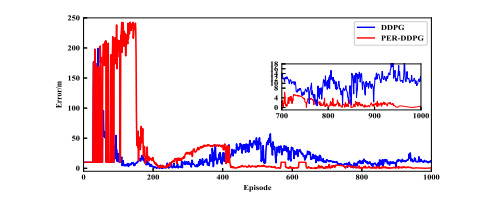
- Figure 6. Steady-state error comparison between DDPG and PER-DDPG.
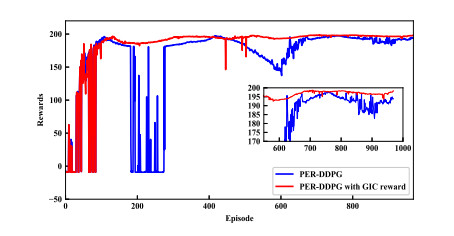
- Figure 7. Accumulated reward comparison between PER-DDPG and PER-DDPG with GIC reward.
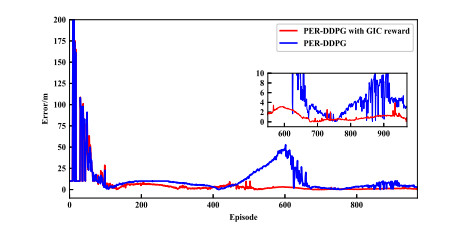
- Figure 8. Steady-state error comparison between PER-DDPG and PER-DDPG with GIC reward.
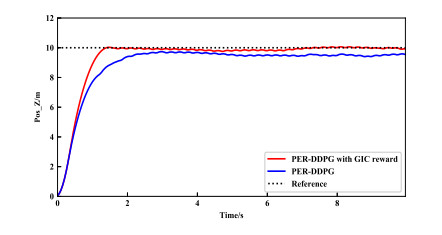
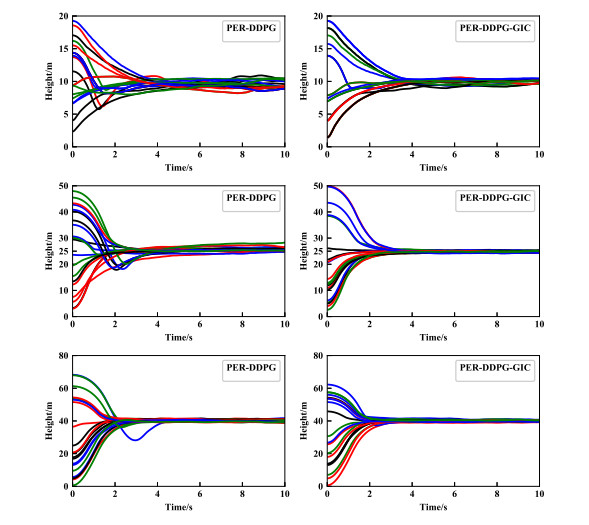
- Figure 9. Height control performance of PER-DDPG and PER-DDPG with GIC reward.
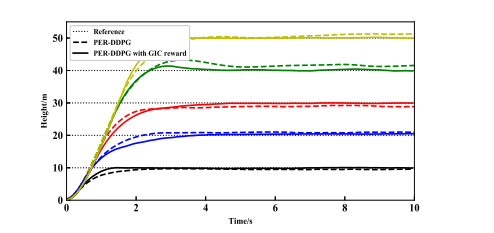
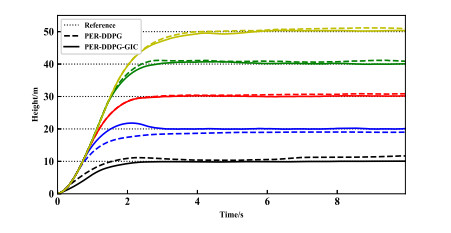
- Figure 10. Response curves at different desired heights.
-
Figure 11. Tracking height 10
$ m $ . -
Figure 12. Tracking height 25
$ m $ . -
Figure 13. Tracking height 40
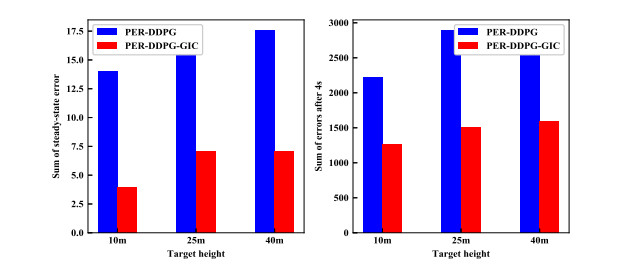
$ m $ . - Figure 14. Error comparison.
-
Figure 15. Total error comparison between 4
$ s $ -10$ s $ . - Figure 16. Actor-critic network of PER-DDPG-GIC for quadrotor control.
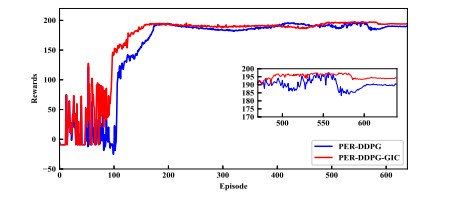
- Figure 17. Accumulated reward comparison between PER-DDPG and PER-DDPG-GIC.
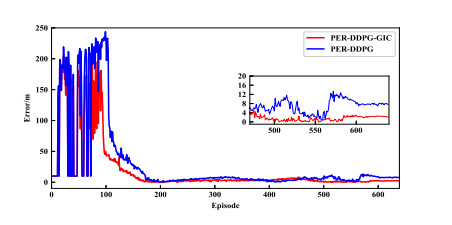
- Figure 18. Steady-state error comparison between PER-DDPG and PER-DDPG-GIC.
- Figure 19. Steady-state error comparison between PER-DDPG and PER-DDPG-GIC.
- Figure 20. Steady-state error comparison between PER-DDPG and PER-DDPG-GIC.
- Figure 21. Steady-state error comparison between PER-DDPG and PER-DDPG-GIC.
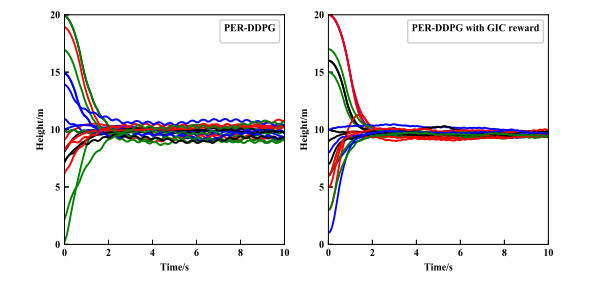
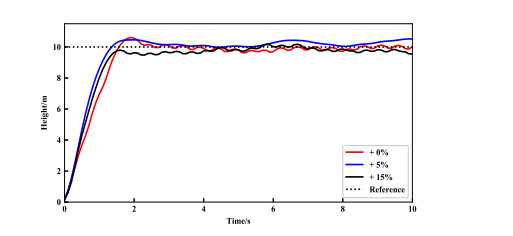
- Figure 22. Generalization capability test of quadrotor with different payloads.
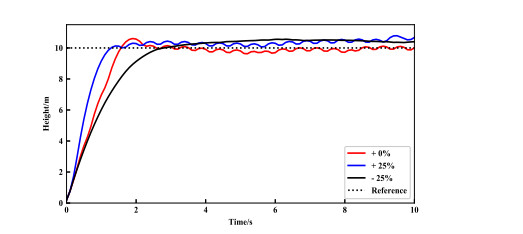
- Figure 23. Generalization capability test of quadrotor with different sizes.
- Figure 24. Quadrotor visual interface.